Linked Data, Big Data and User Science at globo.com
This week in Rio the first Semantic Computing Meeting was held at IGEO (Federal University of Rio de Janeiro). I was pleased to talk about the work we do at Globo.com regarding Linked Data, Big Data, and User Science.
This meeting gathered many researchers and industry practicioneers on Semantic Web, Natural Language Processing, Machine Learning, Big Data, Information Retrieval, and related areas.
Throughout the day it was possible to get some insights about trending topics on these areas, from researchers with great academic background such as Daniel Schwabe (professor at PUC-Rio) to leading industry researchers like Karin Breitman (formerly a professor at PUC-Rio and now chief scientist at EMC Research Brazil).
Moreover, IBM research Brazil was also represented by researchers Cícero dos Santos and Alexandre Rademaker. After Watson development, IBM is now intensively trying to create products with related technologies in their new business area named as Cognitive Computing.
It is interesting to see that we now have an active community interested on these technologies and more and more events are starting to appear, such a Rio Big Data Meetup. Moreover, traditional software development conferences like QCon São Paulo now have Big Data tracks.
About my talk
My main objective was to deliver a walk-through on how Globo.com is interested in getting to know better content, interactions, and users.
The first axis (content) is well developed by ontologies, a triplestore database Virtuoso, and a semantic annotation tool that is well documented (there are lots of examples on my slideshare account).
Now we are intensively working on understanding user interaction. The pipeline starts on the user browser where we capture events. It goes through Kafka messaging service and, finally, to Hbase persistence.
This lead us to semantic user modeling that works by matching our semantic content classification with user interaction. Annotations from interacted content are then added to a user profile with a score representing how relevant a specific entity (person, place, organization and so on) is to a user.
We use spreading activation, a semantic network technique, to assign weights to entities in a user model. It is a form of simple inference to capture related entities with the ones directly annotated in content users interacted with, as depicted below.
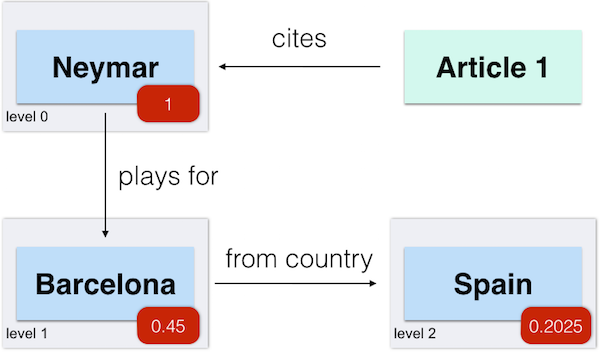
Spreading Activation
Some questions can then be answered by querying a user profile:
- What team does the user support?
- Where does the user lives?
- Which TV celebrity does the user likes most?
For example, this visualization shows my profile in product G1, where the circle size represent entity score and colors represent classes.
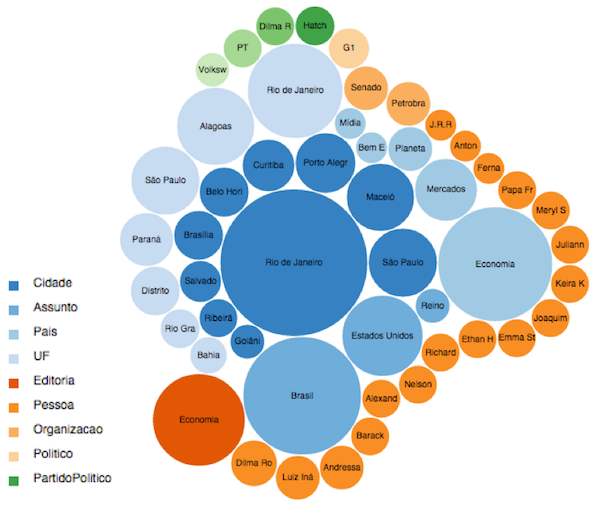
My user profile at G1
Enjoy the slides and feel free to comment.
More about the meeting
Please refer to the meeting website for presenter's contact information.
Comments
comments powered by Disqus